Si queremos comprobar el estado de una url o de una web, podemos utilizar las herramientas wget y curl, y consultar las cabeceras y el código de respuesta.
Revisando la información de las cabeceras, comprobaremos el código de respuesta para saber en qué estado se encuentra la web, y podemos averiguar incluso más info acerca de la web.
En este artículo:
- ¿Cómo podemos averiguar el estado de una URL con wget o curl?
- Averiguar el estado de una web con CURL (buscando el código de respuesta o “response code“)
- Averiguar el estado de una web con WGET (buscando el código de respuesta o “response code“)
- ¿Qué otra información podemos averiguar con curl y wget revisando las cabeceras de una web?
- Podemos utilizar el modo verbose de curl, que muestra info extendida de depuración
- Podemos comprobar redirecciones
- Podemos visualizar el estado de configuración del tipo de caché en Cloudfare (si el sitio usa Cloudfare)
- Podemos averiguar si estamos teniendo problemas de caché Miss
¿Para qué sirve el comando wget y el comando curl?
Estos dos comandos realmente sirven para descargar ficheros de la web, pero con algunos parámetros, podemos ajustar el funcionamiento para que solamente se pida el estado de las cabeceras de la web.
wget y curl fueron hechos para cosas diferentes.
- wget es una herramienta para descargar archivos de servidores.
- curl es una herramienta que permite intercambiar solicitudes con un servidor. Permite transferir datos desde y hacia un servidor.
¿Cómo podemos averiguar el estado de una URL con wget o curl?
Usando diversos parámetros de curl y wget , podremos averiguar el código de respuesta de las cabeceras web, y muchos datos más.
Averiguar el estado de una web con CURL (buscando el código de respuesta o “response code“)
Si ejecutamos curl “a secas” hacia una URL, mostrará el código fuente de la web. Esto no es lo que nos interesa en este caso.
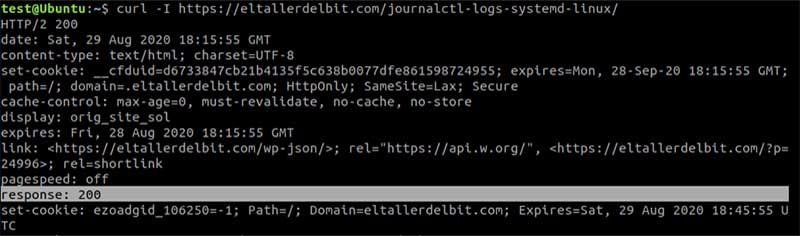
Pero si ejecutamos curl con el parámetro -I, curl mostrará el estado de la cabecera.
curl -I |
curl -I solamente captura las cabeceras, sin descargar toda la pagina
Podemos ver que recibimos el código de respuesta de la web:
response: 200 |
En este caso, ya sabemos que el código de respuesta 200 es OK.
Ayuda de curl:

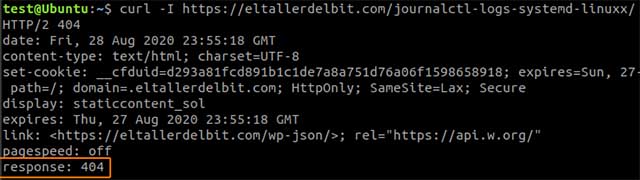
Vemos que si usamos curl para consultar la cabecera de una url que no existe, obtenemos el código 404 correspondiente:
Averiguar el estado de una web con WGET (buscando el código de respuesta o “response code“)
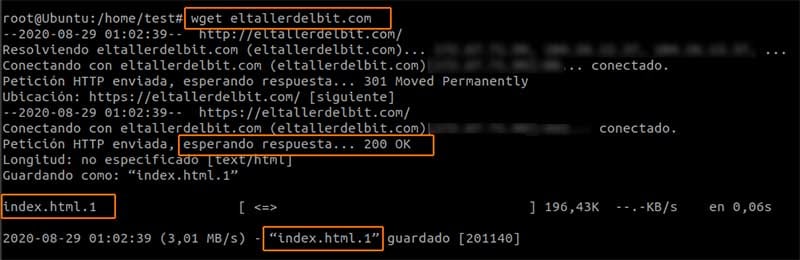
Si usamos wget sin parametros hacia una web, este caso a la página home, descargará la página completa, además de mostrarnos el código de respuesta:
Pero existe otra opción que podemos usar con wget, es el parametro –spider, que realiza la petición del estado de la cabecera, sin descargar la web. Esto coincide mejor con lo que estamos buscando:
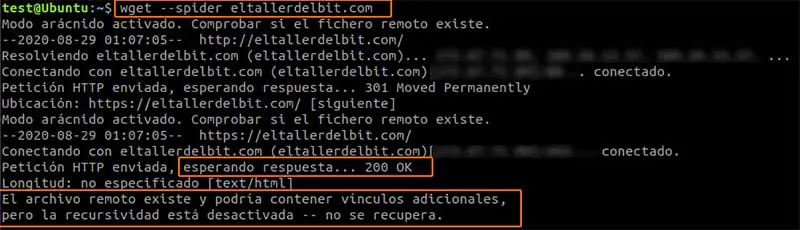
Vemos la ayuda del parámetro –spider

¿Qué otra información podemos averiguar con curl y wget revisando las cabeceras de una web?
Hemos visto cómo podemos averiguar el estado de una web o un enlace, revisando el código de respuesta que nos devuelven wget y curl; pero estos comandos nos pueden ayudar mostrando más info gracias a otras opciones interesantes.
Podemos utilizar el modo verbose de curl, que muestra info extendida de depuración
![]()
curl -v url |
Podemos comprobar redirecciones
Podemos averiguar si la url tiene redirecciones comprobando los códigos de respuesta. (códigos 300 ; 301 es una redirección permanente y 302 una redirección temporal)
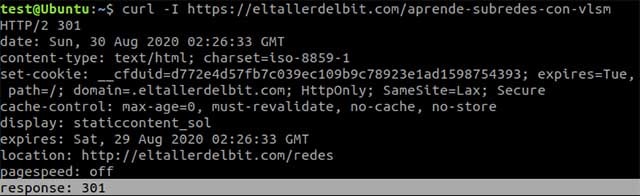
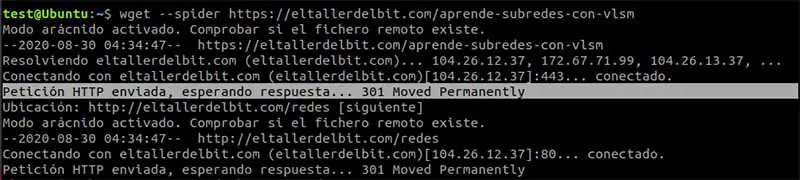
Podemos visualizar el estado de configuración del tipo de caché en Cloudfare (si el sitio usa Cloudfare)
Con curl y el modo verbose, podemos averiguar el servidor, y en el caso de ser Cloudfare, el tipo de caché que utiliza:
curl -I -v https://eltallerdelbit.com/journalctl-logs-systemd-linux/ |
En este caso vemos que se trata de caché dinámica:
< cf-cache-status: DYNAMIC cf-cache-status: DYNAMIC |

Podemos averiguar si estamos teniendo problemas de caché Miss
< x-000-cdn: Miss x-000-cdn: Miss |
Conclusión
Las funciones de los comandos wget y curl para averiguar el código de respuesta de una web y sacar más información extendida de depuración, son enormes. Se trata de dos comandos muy útiles que debemos tener a mano para poder comprobar desde la terminal el estado de una web.